Voice Agent Playbook: AI Phone Calls in Production

TL;DR
- I shipped AI voice receptionists on Retell AI and Twilio that handle real inbound phone calls for businesses, booking appointments and qualifying leads without human intervention
- The model is 10% of what makes a voice agent work in production; conversation flow design, latency management, and graceful human handoff are the other 90%
- Voice agents work best for structured, high-volume inbound calls (bookings, enquiries, triage) and fail at open-ended conversations requiring empathy or complex negotiation
The caller doesn't know they're talking to an AI.
That's the bar. Not "the caller is impressed by the technology." Not "the caller can tell it's AI but doesn't mind." The caller has a straightforward need (book an appointment, ask about availability, report an issue) and the voice agent handles it so naturally that the question of whether it's human or machine never arises.
I've shipped AI voice receptionists in two production platforms: OpenChair for beauty and wellness venues, and OpenTradie for trade businesses. Both handle real phone calls from real customers on real phone numbers. Both book appointments, qualify leads, and route complex requests to humans.
Building a voice agent that works in a demo takes a weekend. Building one that works when a frustrated customer calls at 7am because their hot water system is leaking, and they're talking fast, interrupting, and expecting someone to actually help them right now, that takes deliberate product work. I wrote about the broader experience of building two vertical SaaS platforms end-to-end; voice was the hardest surface in both.
Why voice, why now
Phone calls remain the primary customer contact channel for local services. Salons, tradies, medical practices, restaurants. These businesses live and die by the phone, and most of them miss 20% to 40% of inbound calls because the owner is with a client, on the road, or eating lunch.
Every missed call is a missed booking. For a salon averaging $80 per appointment, missing 5 calls a day is $400 in lost revenue. Per day. For a plumber charging $150 per callout, missing 3 calls a day is $450. The maths is painful and obvious.
The existing solutions are voicemail (customers hang up), call centres (expensive, generic, no access to booking systems), and "we'll call them back" (by which time they've called your competitor). An AI voice receptionist that answers every call, 24/7, with access to the booking calendar and the ability to actually schedule appointments, changes the economics of running a service business.
The technology is ready. Retell AI handles the speech-to-text and text-to-speech pipeline with low enough latency to feel conversational. Twilio handles telephony. The missing piece isn't the technology. It's the product design.
How much latency can a voice agent tolerate before callers drop off?
In a chat interface, 2 seconds of response time is acceptable. In a phone conversation, 2 seconds of silence is an eternity.
Human conversation has a rhythm. Turn-taking gaps average 200 to 300 milliseconds. When the gap stretches beyond 500 milliseconds, the caller perceives something is wrong. They repeat themselves. They say "hello?" They get frustrated. By 1.5 seconds, you've lost them.
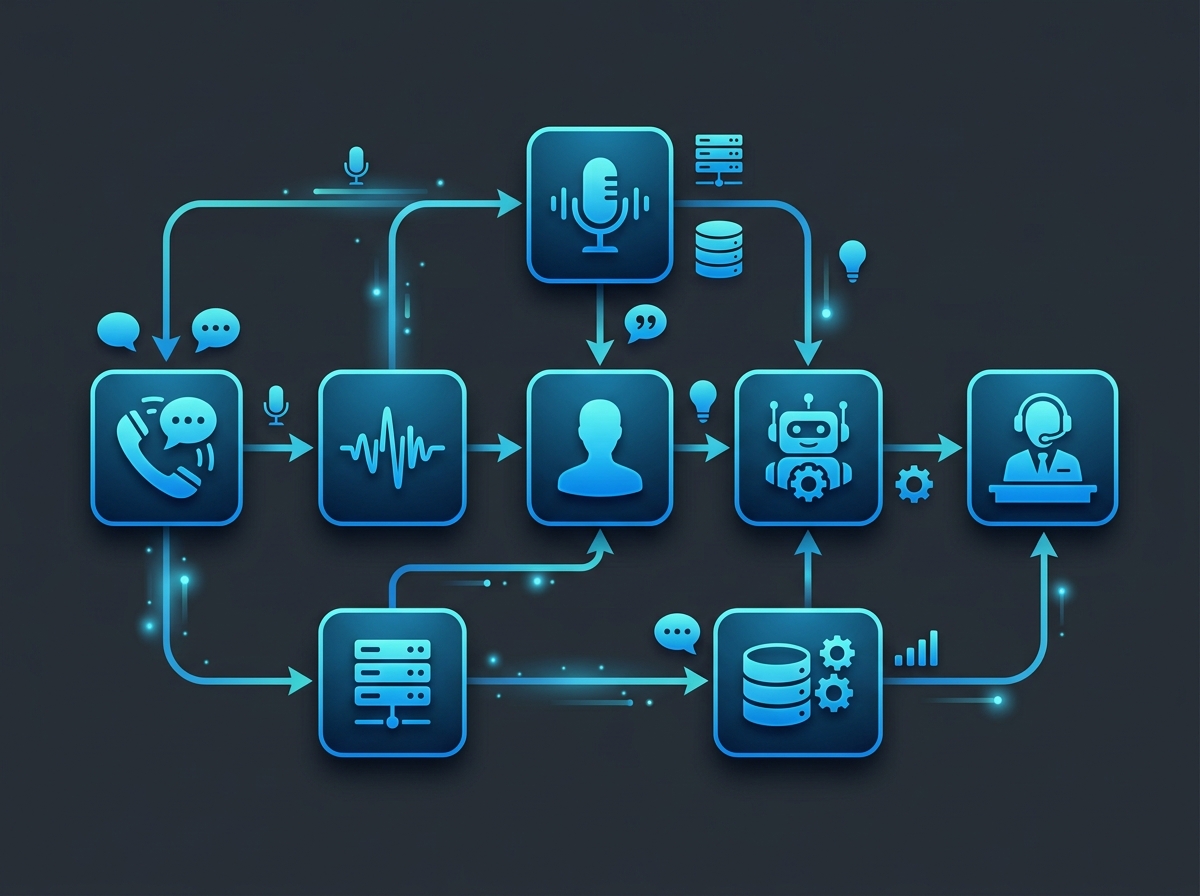
The voice agent latency stack looks like this:
- Speech-to-text: 100 to 300ms (depends on the STT engine and whether you're streaming or waiting for the full utterance)
- LLM inference: 200 to 800ms (depends on the model, prompt length, and whether you're using a reasoning model)
- Text-to-speech: 50 to 200ms (most modern TTS engines are fast)
- Network round trips: 50 to 150ms (accumulated across the pipeline)
Total: 400ms to 1,500ms. The difference between the low end and the high end is the difference between "feels natural" and "feels broken."
The product decisions that control latency:
Model selection matters more for voice than for any other AI interface. A reasoning model that produces a slightly better response in 800ms loses to a faster model that produces a good-enough response in 200ms. For voice, speed IS quality. I use lighter models for the conversational layer and only route to heavier models when the agent needs to make a complex decision (like resolving a scheduling conflict).
Streaming is non-negotiable. Wait for the full LLM response before starting TTS, and you've added 300 to 500ms to every turn. Stream the LLM output directly into the TTS engine, and the voice starts speaking while the model is still generating. The caller hears the beginning of the response almost immediately.
Pre-computation saves critical milliseconds. If the caller says "I'd like to book a haircut," the agent needs to check availability. Don't wait for the availability lookup to complete before responding. Start speaking ("Let me check what's available for you...") while the system queries the calendar in the background. This is natural human behaviour (people say "let me look at that" while they're looking), and it masks latency.
Conversation flow is product design, not prompt engineering
The biggest mistake I see in voice agent implementations is treating the conversation as a single long prompt. "You are a receptionist for a hair salon. Answer customer questions and book appointments."
That works in a demo. In production, it produces an agent that meanders, asks unnecessary questions, forgets context mid-conversation, and doesn't know when to give up and hand off to a human.
Production voice agents need structured conversation flows with defined states, transitions, and exit conditions. Not rigid IVR-style decision trees. Flexible flows with guardrails. The handbook chapter on AI UX and interaction design covers the broader principles; voice is where those principles face their strictest test.
Opening: Greet the caller. Identify the intent. This needs to happen in the first 10 seconds. If the agent is still asking clarifying questions at the 30-second mark, the caller is already annoyed.
Information gathering: Collect what's needed to fulfil the intent. For a booking: service type, preferred date/time, any provider preference. Ask one question at a time. Don't front-load three questions in a single turn ("What service would you like, what day works for you, and do you have a preferred stylist?"). That works in text. It overwhelms in voice.
Confirmation: Repeat back the key details. "So that's a cut and colour with Sarah on Thursday at 2pm. Does that sound right?" This is where errors get caught. Skip it and you'll book wrong appointments.
Edge case handling: The caller wants a service you don't offer. The requested time isn't available. They want to speak to the owner about a complaint. Each of these needs a defined path, not an open-ended "figure it out" prompt.
Handoff: When the conversation exceeds the agent's scope, transfer to a human cleanly. "Let me connect you with Sarah directly for that. One moment." Not "I'm sorry, I'm not able to help with that." The first is service. The second is a dead end.
I designed conversation flows for two fundamentally different verticals. For beauty and wellness, calls are typically calm, scheduled, and preference-driven ("I'd like balayage with whoever is available next week"). For trades, calls are often urgent, stressed, and problem-driven ("There's water coming through my ceiling right now"). The emotional register is completely different, and the conversation flow needs to match. A cheery "What service are you interested in?" response to a panicking homeowner is tone-deaf.
The handoff is the hardest part
Getting the AI to handle 80% of calls is relatively straightforward. Building a graceful handoff for the other 20% is where most implementations fail.
The failure modes:
Silent transfer. The agent routes to a human without context. The caller has to explain everything again. This is worse than no AI at all, because the caller already invested time in the AI conversation and now has to repeat it.
Abandoned transfer. The agent tries to transfer, but no human is available. The caller gets voicemail after a 2-minute AI conversation. Infuriating.
Scope creep. The agent tries to handle something it shouldn't. A complaint. A pricing negotiation. A complex rescheduling with multiple dependencies. The agent produces a response that sounds confident but is wrong, and the business doesn't find out until the customer shows up at the wrong time.
The fix is a combination of clear scope boundaries (the agent knows exactly what it can and can't handle), context-rich handoff (the human receives a summary of the conversation before they pick up), and fallback design (if no human is available, the agent takes a message with a specific callback commitment rather than leaving the caller stranded).
The handoff design deserves as much product attention as the happy path. Maybe more, because the handoff scenarios are the ones where the customer is already slightly frustrated.
When voice agents work (and when they don't)
Voice agents work well for:
- High-volume, structured inbound calls (bookings, availability enquiries, appointment confirmations)
- After-hours coverage (calls that would otherwise go to voicemail)
- Triage and routing (qualifying the call and connecting to the right person)
- Information lookup (hours, directions, service descriptions, pricing)
Voice agents struggle with:
- Emotional conversations (complaints, disputes, bad news)
- Complex negotiations (pricing discussions, custom quotes with many variables)
- Multi-party calls (conference calls, translator-mediated conversations)
- Conversations requiring deep domain expertise (medical triage, legal advice)
The pattern from boring agents that work applies directly, and the full catalogue of agentic AI patterns in the handbook covers how to structure these workflows: target patience-heavy tasks, not judgment-heavy ones. A booking call is patience-heavy (structured, repetitive, follows a known pattern). A complaint call is judgment-heavy (requires empathy, context, authority to make decisions). Build agents for the first category. Keep humans on the second.
The production checklist
Before shipping a voice agent, verify:
- End-to-end latency under 800ms for 90th percentile responses
- Conversation flow tested with 50+ real scenario variations (not just the happy path)
- Handoff tested for every scope boundary (what happens when the agent reaches its limit?)
- Fallback tested for no-human-available (voicemail with context, callback commitment)
- Monitoring in place for conversation completion rate, handoff rate, and customer satisfaction
- Caller consent and compliance verified for your jurisdiction (recording laws, AI disclosure requirements)
The voice agent that earns trust is the one that handles the routine brilliantly and hands off the exceptions gracefully. Both halves matter equally.
Frequently Asked Questions
Do callers need to be told they're talking to an AI?
This varies by jurisdiction and is evolving. Some regions require explicit AI disclosure. Others don't. My recommendation: check your local regulations, but also consider that transparency builds trust. A brief "You're speaking with our AI assistant" at the start doesn't hurt call completion rates in my experience, and it sets appropriate expectations.
What's the cost per call for a voice agent?
For a typical 2-minute inbound booking call: STT, LLM inference, and TTS combined run $0.03 to $0.10 depending on model choices and conversation length. Twilio charges $0.01 to $0.02 per minute for voice. Total: roughly $0.05 to $0.15 per call. Compare that to a human receptionist at $25 to $35 per hour handling 15 to 20 calls per hour ($1.25 to $2.30 per call). The economics are compelling for high-volume call patterns.
Can you use open-source models to reduce voice agent costs?
Yes, and the quality gap is closing. Open-source STT (Whisper) and TTS (Piper, Coqui) models are viable for many use cases. The tradeoff is typically higher latency or lower naturalness compared to commercial APIs. For cost-sensitive deployments with high call volume, self-hosted models can reduce per-call costs significantly. For quality-sensitive deployments, commercial APIs are still worth the premium.
Logan Lincoln
Senior AI product builder based in Brisbane, Australia. Nine years in regulated B2B SaaS and recent hands-on AI engineering through production-grade AI reference builds.