3 Agentic AI Patterns from Google's Playbook
TL;DR
- Google's AI Agent Handbook is vendor marketing wrapped around genuinely excellent architectural patterns
- The Deep Research, Multi-Agent Orchestration, and Integration Imperative patterns are stack-agnostic and worth internalising
- The real challenge isn't implementing agents. It's identifying which workflows actually need agency
Google's AI Agent Handbook is a Gemini sales pitch wrapped around genuinely excellent architecture. Vertex AI, BigQuery, Chrome Enterprise: the document is designed to sell the Google ecosystem. That's expected. Google doesn't publish 50-page documents out of generosity.
But the architectural patterns underneath the vendor positioning are stack-agnostic and worth stealing. I've distilled these and other production-tested patterns into the handbook chapter on agentic AI patterns. Whether you're building on Google, OpenAI, or Anthropic, three patterns stood out.
Pattern 1: Deep Research
The handbook describes a pattern that moves beyond simple summarisation into active planning, gathering, and synthesis. An agent doesn't just answer a question. It decomposes the question into sub-queries, plans a research strategy, gathers information from multiple sources, and synthesises a coherent answer.
This matters for product builders because it's the blueprint for accelerating product discovery. Think about the research workflows your team runs today: competitive analysis, user research synthesis, technical feasibility assessments. Most of these follow the same plan-gather-synthesise loop, but they're done manually, inconsistently, and slowly.
The Deep Research pattern gives you a framework for automating the structured parts of that loop without pretending the unstructured parts (judgment, prioritisation, strategic framing) can be automated away. The agent handles breadth. The human handles depth.
If you're building product discovery tools, internal research assistants, or any workflow where someone is currently spending hours gathering and consolidating information, this is your pattern.
Pattern 2: Multi-Agent Orchestration
The concept of specialised agents collaborating to solve a problem is perhaps the most important architectural pattern in the handbook. Rather than building one monolithic agent that tries to do everything, you design specialised agents (one for ideation, one for scoring, one for execution) and orchestrate their collaboration.
This mirrors what I've learned building production AI systems with multi-model orchestration. Routing different tasks to different models based on cost-quality-latency tradeoffs is a design discipline, not a vendor selection. When you extend this thinking to agents, the same principle holds: specialisation beats generalisation.
The practical implications for system design are significant. A multi-agent architecture lets you:
- Iterate independently. Improve your scoring agent without touching your ideation agent.
- Scale selectively. Route high-value tasks to more capable (and expensive) agents while keeping routine work on lighter models. Be warned: the cost of a manager agent auditing every worker output is a 2,500% audit tax if you don't design your confidence routing carefully.
- Fail gracefully. When one agent produces poor output, the orchestration layer can detect it and route to a fallback without the entire system collapsing.
This is a pattern every product builder should be exploring, regardless of tech stack. The question isn't whether to use multi-agent orchestration. It's how to decompose your problem space into the right set of specialised agents.
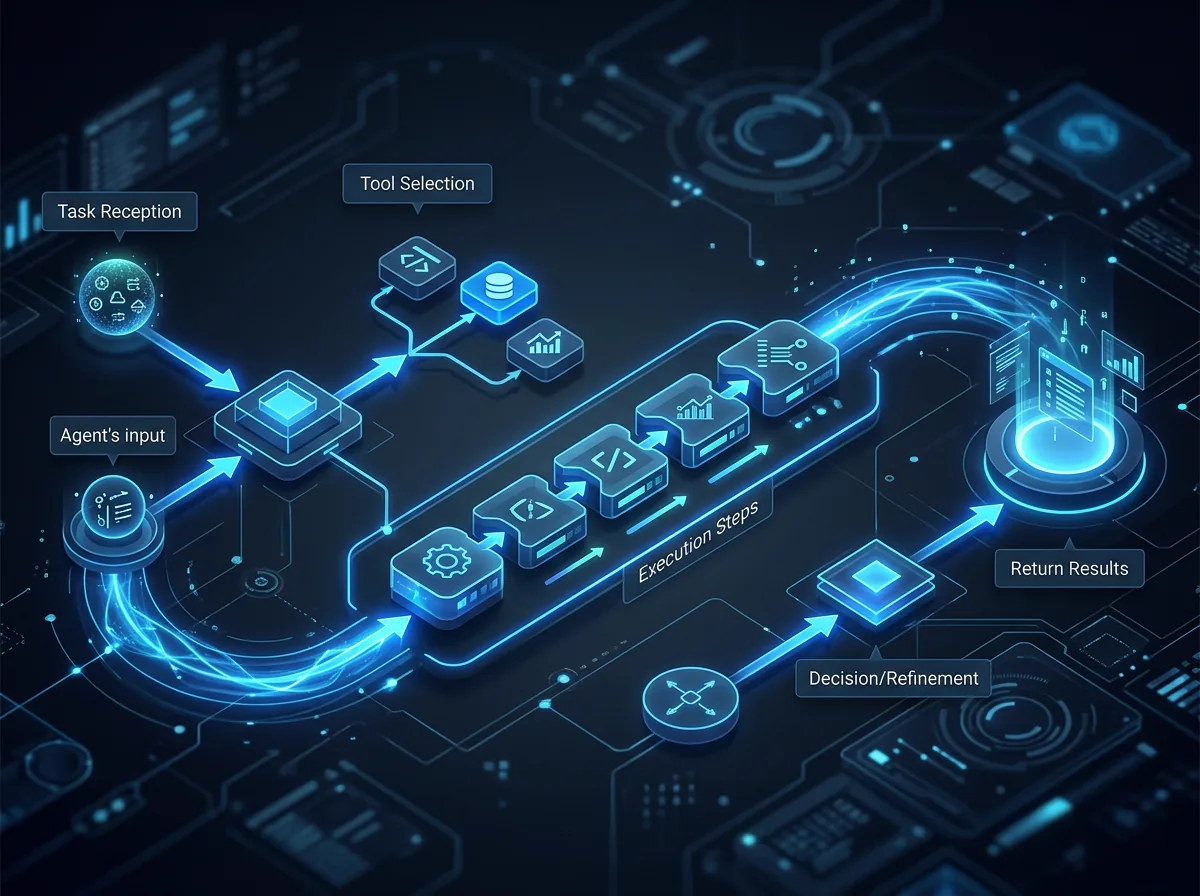
Pattern 3: The Integration Imperative
The handbook rightly identifies that an agent's value is capped by its access to live enterprise data. An agent that can reason brilliantly but can only see what's in its context window is a parlour trick. An agent connected to your CRM, documentation, codebase, and operational data is a genuine productivity multiplier.
This is where most enterprise AI initiatives stall. The models are capable enough. The problem is that the integration work is unglamorous, slow, and politically fraught. Who owns the data? What's the access model? How do you handle PII? What happens when the source system changes its schema?
For product builders, the Integration Imperative reframes how you should prioritise your roadmap. Before you build clever agent capabilities, audit what data your agents can actually access. The most sophisticated reasoning in the world is useless if the agent is operating on stale, incomplete, or siloed information.
This connects directly to governance. Every new integration is a new surface area for data exposure, access control decisions, and compliance considerations. If you're not thinking about governance alongside integration, you're building technical debt that will eventually become a blocker.
How do you decide which workflows actually need an agent?
The patterns in Google's handbook are sound. The architectures are well-considered. The use cases are compelling.
But the primary challenge for us as product builders isn't implementing these patterns. It's defining the workflows that actually require agency.
Not every process needs an agent. Not every research task needs Deep Research. Not every workflow benefits from multi-agent orchestration. The hard work is in honest assessment: where does agency genuinely create value versus where are you adding complexity for the sake of appearing innovative?
The best product builders I know are asking this question before they write a single line of agent code. They're mapping their workflows, identifying where human judgment is the bottleneck versus where information gathering is the bottleneck, and only reaching for agentic patterns where the latter dominates. The best agents aren't general-purpose thinkers. They're narrow SOPs wrapped in code.
Don't read Google's handbook for the Gemini product features. Read it for the use cases. It's a solid primer on what "good" looks like in the agentic era, if you can separate the patterns from the pitch.
Frequently Asked Questions
Should product builders adopt agentic AI patterns now or wait?
Now, but selectively. The patterns described here (Deep Research, Multi-Agent Orchestration, the Integration Imperative) are mature enough to build on. The risk isn't in adopting them too early. It's in adopting them for the wrong workflows. Start with high-volume information gathering tasks where the plan-gather-synthesise loop is well-defined.
How do you evaluate whether a workflow needs an agent or simpler automation?
Ask whether the task requires dynamic decision-making during execution. If the steps are known in advance and the inputs are predictable, a deterministic workflow (or even a well-crafted prompt) will outperform an agent. Agents earn their complexity when the path through the task depends on intermediate results, when the system needs to decide what to do next based on what it just learned.
Are these patterns specific to Google's stack?
No. The vendor-specific implementation details are Google's. The architectural patterns (decomposing research into plan-gather-synthesise, orchestrating specialised agents, and prioritising data integration) transfer cleanly to any stack. I've applied similar patterns building on Anthropic and OpenAI. The concepts are universal; only the plumbing changes.
Logan Lincoln
Senior AI product builder based in Brisbane, Australia. Nine years in regulated B2B SaaS and recent hands-on AI engineering through production-grade AI reference builds.


