The 2,500% Audit Tax: The Math That Will Kill Your Multi-Agent P&L

TL;DR
- A manager model auditing every worker output can increase per-task cost by 2,500%, and most pricing models can't absorb that
- The fix is a spot-check architecture: only route low-confidence outputs to the manager, let high-confidence outputs pass through
- Tuning your worker to 80% high-confidence can cut your blended cost by 75% with a single architectural decision
Your margin is the first casualty of your agentic roadmap.
I wrote recently about the Hard Hat era, multi-agent systems where AI managers oversee AI workers. The architectural pattern is sound. The reliability benefits are real. But there's a financial reality underneath the architecture that most product teams aren't modelling, and it will destroy unit economics if left unaddressed.
If you're building a manager-worker architecture, you need to calculate your "Audit Tax" immediately. Before the roadmap review. Before the pricing discussion. Before you commit to a reliability target you can't afford.
Here is the math.
The cost structure of manager-worker systems
Let's assume a standard architectural split for 2026:
The Worker: An efficient small language model (SLM) executing a defined SOP. Extract data, classify a ticket, draft a response. Narrow, fast, cheap.
- Cost estimate: ~$0.20 per 1M tokens
The Manager: A reasoning-heavy large language model (LLM) checking accuracy, handling edge cases, and making judgment calls.
- Cost estimate: ~$5.00 per 1M tokens
The manager is roughly 25x more expensive than the worker. That ratio isn't a bug. It reflects the genuine difference in model capability. Reasoning is expensive. Execution is cheap. That's the whole point of the multi-model orchestration architecture: use the expensive model only where you need it.
The problem is that the default instinct for product managers is: "I want 100% reliability, so the manager should check every single output."
That instinct will bankrupt your AI feature.
How much does the audit tax cost in multi-agent systems?
Let's model a single task, say, drafting an email response to a customer inquiry.
Worker execution: ~1,000 tokens generated. Cost: $0.0002.
Manager audit: ~1,000 tokens reading the context plus ~100 tokens of reasoning to validate. Cost: ~$0.005.
Total cost with 100% audit: $0.0052 per task.
If you simply let the worker run without audit, it costs $0.0002 per task.
If you add a 100% audit layer, you have just increased your unit cost by 2,500%.
Twenty-five hundred percent. For the same output. The email response is identical in most cases, because the worker got it right. But you paid the manager to confirm that the worker got it right, every single time, regardless of whether the confirmation was necessary.
At 10,000 tasks per day, the difference is $2 versus $52. At 100,000 tasks per day, it's $20 versus $520. At enterprise scale, you're looking at the difference between a profitable AI feature and one that hemorrhages cash with every interaction.
Most pricing models cannot absorb this. The handbook chapter on AI business viability covers how to model these costs before you commit to a pricing structure. If you priced your AI feature based on the worker's inference cost and then added a 100% manager audit for reliability, you've just vaporised your margin. The feature works beautifully. The accountant is screaming.
The micromanager problem
This is what I call the "Micromanager Architecture," and it's the default that most teams build without thinking about it.
The instinct makes sense. You want reliability. You've seen the 95% Trap, compounding error rates across multi-step workflows. You know that a single hallucination in a customer-facing output can do real damage. So you audit everything.
But micromanaging your AI workers has the same problem as micromanaging your human workers: it's expensive and it doesn't scale. Worse, it creates a bottleneck at the management layer. If the manager has to review every output, the manager's throughput becomes your system's throughput. And the manager's cost becomes your system's cost.
The question isn't whether to audit. It's how to audit intelligently.
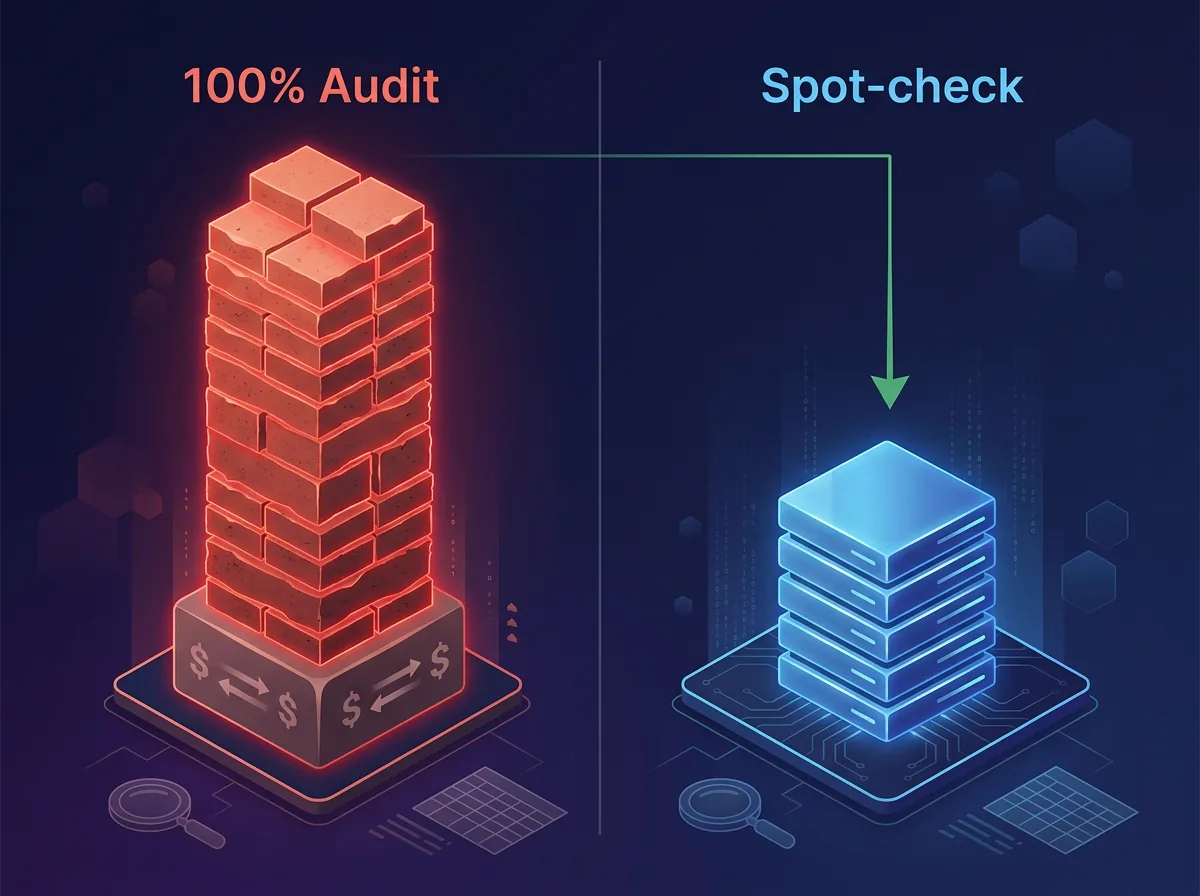
The spot-check architecture
Instead of a micromanager, build a spot-check architecture. The principle is simple: only escalate to the expensive model when the cheap model isn't confident in its own output.
Scenario A, High Confidence (>90%): Worker executes the task. The model's confidence score exceeds your threshold. No audit. Output goes directly to the next step or to the user. Cost: $0.0002.
Scenario B, Low Confidence (below 90%): Worker executes the task. The confidence score falls below your threshold. The manager steps in to review, validate, or fix the output. Cost: $0.0052.
If you can tune your worker to produce high-confidence outputs 80% of the time, your blended cost per task drops from $0.0052 to approximately $0.0012.
You just saved 75% of your margin with one architectural decision.
The math: (0.80 × $0.0002) + (0.20 × $0.0052) = $0.00016 + $0.00104 = $0.0012.
That's the difference between a feature that scales profitably and one that becomes more expensive with every user you add.
How to build effective confidence scoring
The spot-check architecture only works if your confidence scoring is reliable. A worker that's confident about wrong answers is worse than a worker that escalates everything, because you get the cost savings but lose the reliability.
There are several approaches, and they can be combined:
Model-native confidence. Most models can express uncertainty. Ask the worker to rate its own confidence or generate multiple candidate responses and measure agreement. High agreement across candidates suggests high confidence.
Rule-based validation. For structured outputs (data extraction, classification, form filling), validate against known constraints. Does the extracted date fall within a reasonable range? Does the classification match one of the allowed categories? Does the email address match a valid format? These checks are nearly free and catch a large class of errors without invoking the manager.
Historical calibration. Track the worker's actual accuracy against its confidence scores over time. If the worker claims 95% confidence but is actually correct 85% of the time at that threshold, adjust the threshold. Calibration turns subjective model confidence into a reliable routing signal.
Domain-specific heuristics. In some domains, certain input patterns are known to be harder. Longer documents, ambiguous language, unusual formatting. Route these to the manager proactively based on input characteristics rather than waiting for the worker to struggle.
The goal is to make the confidence score a genuine predictor of accuracy, not just a number the model generates. This requires investment in evaluation infrastructure, but that investment pays for itself many times over in reduced manager inference costs.
Pricing implications
If you're building multi-agent products for customers, the audit tax needs to be reflected in your pricing strategy.
Reliability is a premium feature. Enterprise customers who need 99%+ accuracy on every output are asking for a higher audit rate, which means higher inference cost. That's a different tier than a customer who's comfortable with 90% accuracy and human review for the rest. And if your AI feature only assists a human workflow rather than replacing it, the audit tax compounds the copilot margin trap: you're paying for both the worker inference and the manager audit, while the user still does most of the work.
Model your pricing around three variables:
- Base task cost (worker inference)
- Audit rate (percentage of tasks routed to manager)
- Failure cost (what a wrong output costs the customer)
Customers with high failure costs will pay for high audit rates. Customers with low failure costs won't. Offering a single reliability tier at a single price means you're either overcharging the low-risk customers or subsidising the high-risk ones. Neither is sustainable.
The best multi-agent products will offer configurable reliability: let the customer set the confidence threshold based on their risk tolerance and budget. That's genuine product differentiation built on architectural understanding, not just a better prompt. This pricing logic feeds directly into the broader shift from per-seat to outcome-based pricing.
Frequently Asked Questions
Is 80% high-confidence output realistic for most use cases?
It depends heavily on the task and the worker model's fit for it. Well-scoped tasks with clear inputs and structured outputs (data extraction, classification, template-based generation) can often exceed 90% high-confidence. Open-ended generation tasks or those with ambiguous inputs will be lower. The key is measuring your actual confidence distribution before committing to a cost model. Run the worker on a representative sample and see where the distribution falls.
Can you use a cheaper model as the manager instead of a frontier LLM?
Yes, and you should explore this. The manager doesn't always need frontier-level reasoning. For many audit tasks, a mid-tier model can validate a worker's output effectively. The cost ratio will be smaller (maybe 5x instead of 25x), which makes 100% audit more viable in some cases. Match the manager's capability to the audit's actual complexity, not to the hardest edge case you can imagine.
What happens when the worker gets something wrong and the confidence score was high?
This is the spot-check architecture's failure mode, and it will happen. The mitigation is layered: downstream validation rules catch some errors, periodic random sampling catches systematic drift, and customer feedback loops catch what automated checks miss. No architecture eliminates errors entirely. The goal is to make the error rate acceptable for the use case while keeping costs viable. Monitor, calibrate, and adjust the confidence threshold continuously.
Logan Lincoln
Senior AI product builder based in Brisbane, Australia. Nine years in regulated B2B SaaS and recent hands-on AI engineering through production-grade AI reference builds.


